· Zen HuiFer · Learn · 需要5 分钟阅读
How weak is OpenAI o1?
Assessing OpenAI's o1 model's performance on the ARC-AGI Pub dataset reveals it outperforms GPT-4o but requires more computation time. The model showcases potential yet has limitations.

How weak is OpenAI o1?
https://arcprize.org/blog/openai-o1-results-arc-prize
OpenAI o1 results on ARC-AGI Pub
ARC Award Testing and Explanation of OpenAI’s New o1 Model
In the past 24 hours, we have received new releases from OpenAIo1-previewando1-miniModels that have been specially trained to simulate reasoning. Before providing the final answer, these models have extra time to generate and refine inference markers.
Hundreds of people asked how o1 performed at the ARC Awards. Therefore, we tested it using the same baseline testing tools as evaluating Claude 3.5 Sonnet, GPT-4o, and Gemini 1.5. The results are as follows:
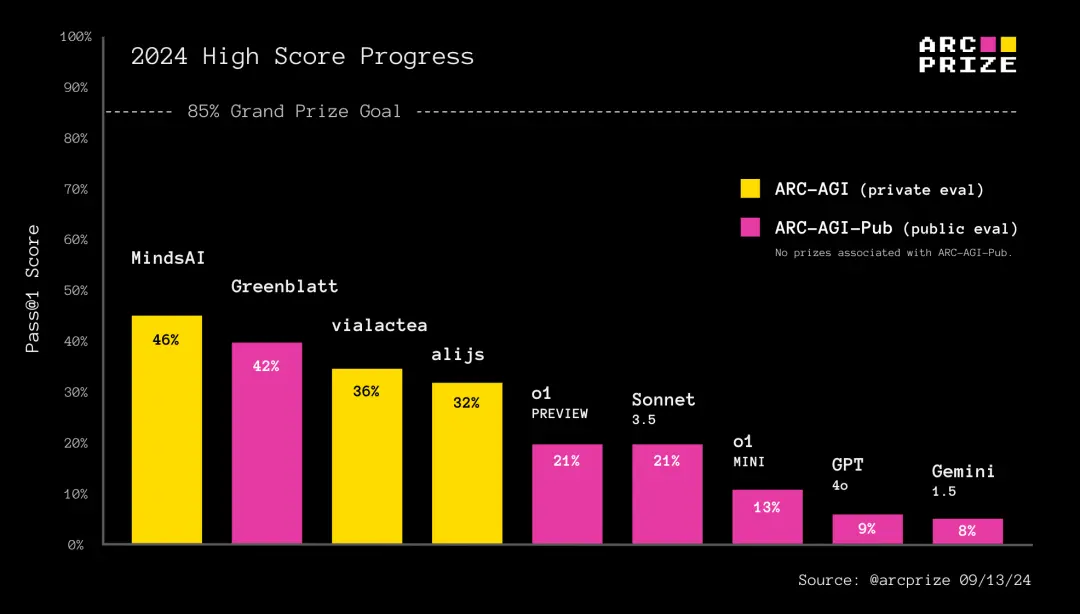
Is o1 the new paradigm of AGI? Will the scale expand? Compared to the average score on ARC-AGI, there is a significant difference in the performance of o1 on IOI, AIME, and many other impressive benchmark test scores. How can this be explained?
There are many things to talk about.
Thought chain
O1 By applying it during training and During testing, reasoning fully implements the Chain of Thought (CoT) paradigm of ‘let’s think step by step’.
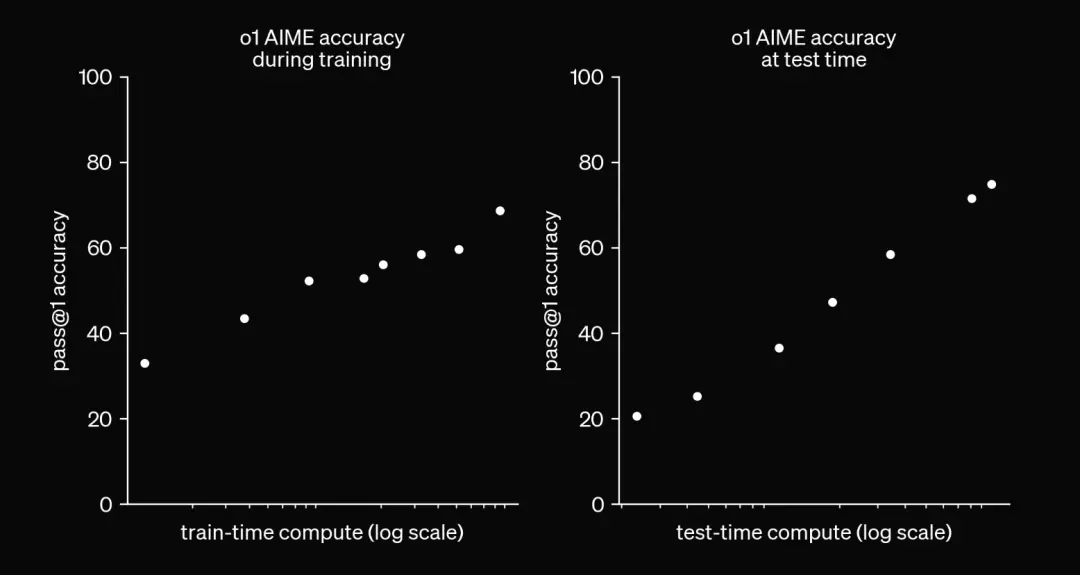
Source: OpenAI “Learning Reasoning with LLMs”.
In fact, when the intermediate step sequence is well reflected in the synthesized CoT training data, the likelihood of o1 making errors during task execution is much smaller.
During training, OpenAI stated that they have developed a new reinforcement learning (RL) algorithm and a high data efficiency process utilizing CoT.
This means that the basic source of o1 training is still a fixed set of pre training data. But OpenAI can also generate a large number of synthetic CoTs that simulate human reasoning to further train models through RL. An unresolved question is how OpenAI chooses generated CoTs for training?
Although we have limited knowledge of the details, the reward signals of reinforcement learning are likely achieved through validation (in formal fields such as mathematics and code) and manual labeling (in informal fields such as task decomposition and planning).
During inference, OpenAI stated that they are using RL to hone o1’s CoT and refine its strategy for use. We can speculate that the reward signal here is some kind of actor+critic system, similar to the system previously released by OpenAI. They apply search or backtracking to the generated inference markers during inference.
Calculate during testing
The most important aspect of o1 is that it demonstrates working examples of applying CoT inference search to informal languages rather than formal languages such as mathematics, code, or lean.
Although using CoT to increase training time extension is noteworthy, the most important new story is testing time extension.
We believe that iterative CoT can indeed achieve greater generalization. Automatic iterative re prompting enables the model to better adapt to novelty, similar to the fine-tuning used by the MindsAI team during testing.
If we only make one inference, we can only reapply the memory program. But by generating intermediate output CoT or programs for each task, we unlock the ability of combinatorial learning program components to adapt.
This technology is a method to overcome the first problem of generalization in large language models: the ability to adapt to novelty. Although it may be fine tuned during testing, it ultimately remains limited.
When artificial intelligence systems are allowed to perform variable amounts of testing calculations (such as the number of inference markers or search time), there is no objective way to report a single benchmark score because it is relative to the allowed calculations. This is what this chart displays.
More calculations mean higher accuracy.
When OpenAI releases o1, they can allow developers to specify how much computation or time to optimize CoT during testing. On the contrary, they ‘hard coded’ a point in the continuum during testing and concealed the implementation details from the developers.
By calculating different testing times, we can no longer simply compare the outputs between two different artificial intelligence systems to evaluate relative intelligence. We still need to compare calculations efficiency 。
Although OpenAI’s announcement did not share efficiency data, it is exciting that we are now entering a period focused on efficiency. Efficiency is crucial for defining AGI, which is why the ARC Award imposes efficiency limitations on award-winning solutions.
Our prediction We expect to see more benchmark charts comparing accuracy and calculations during testing in the future.
ARC-AGI Pub Model Baseline
OpenAI o1-previewando1-miniOn the ARC-AGI public evaluation dataset, it outperforms all other datasetsGPT-4o 。 o1-previewIn terms of accuracy, it is comparable to Anthropic’s Claude 3.5 Sonnet, but it takes approximately 10 times longer to achieve results similar to Sonnet.
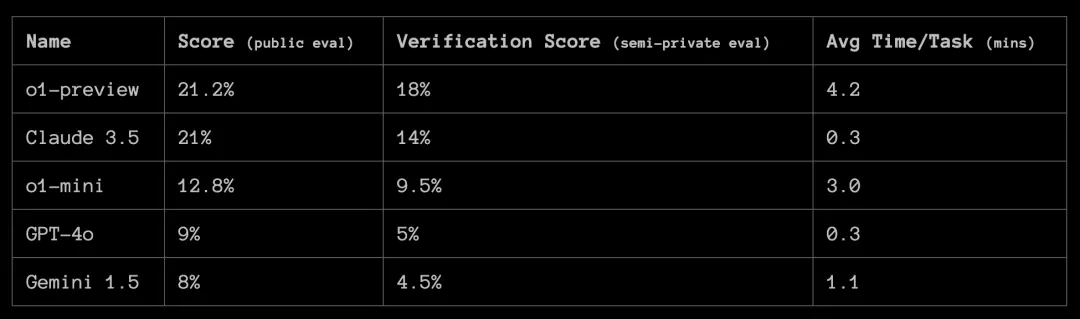
In order to obtain baseline model scores on the ARC-AGI Pub ranking, we used and testedGPT-4oSame baseline prompt. When we test and report results on pure models like o1, our goal is to measure the performance of the basic model as much as possible without any optimization.
Others may discover better ways to promote CoT style models in the future, and if validated, we are happy to add them to the rankings.
The performance improvement of O1 is indeed accompanied by time costs. 400 public tasks took 70 hours, andGPT-4oIt only took 30 minutes with Claude 3.5 Sonnet.
You can use our open-source Kaggle notebook as a baseline testing tool or as a starting point for your own approach. The submission of SOTA on public rankings is the result of clever technology and cutting-edge models.
Perhaps you can figure out how to use o1 as a basic component to achieve higher scores in a similar way!